
Preparation for Installing a MapR Cluster.
Prepare for Installation
Intro
When you have finished with this section, you will be able to:
Identify Node Types
Node Types
Data Nodes:

- Store data
- Run application jobs
- Process table data
Control Nodes:
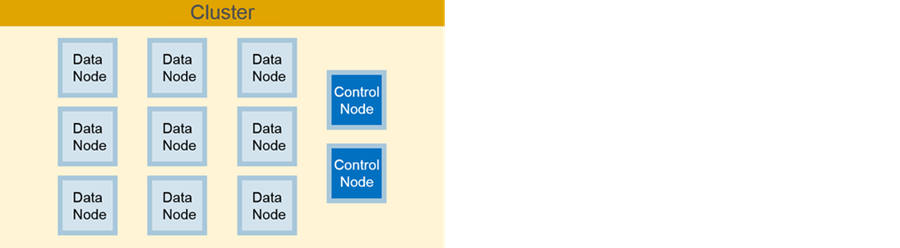
- Manage the cluster
- Establish communication between cluster and client nodes
Client Nodes:
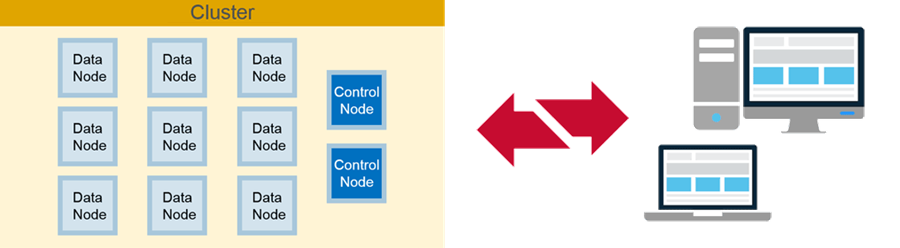
- Submit jobs
- Retrieve data
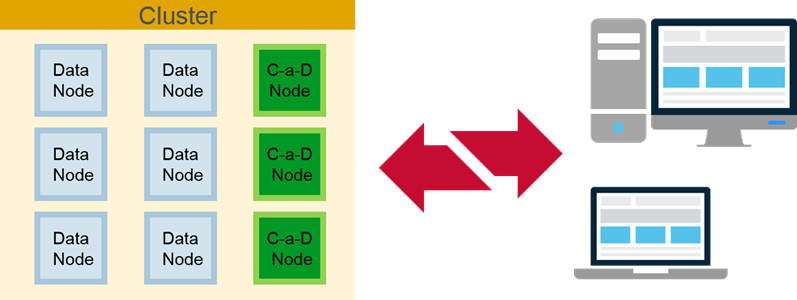
Control-As-Data Nodes:
Smaller clusters may combine control and data nodes
Prepare and Verify Cluster Hardware
Prepare Cluster Hardware
- Critical! Verify all nodes meet requirements
- Failure to verify all nodes is a common cause of failure during installation
- Visit maprdocs.mapr.com/51/#AdvancedInstallation/PreparingEachNode.html for the latest information
Cluster requirements
- Minimum requirements are just that: minimum
- Not necessarily recommended for production
- Optimum specifications vary depending on:
- Size of the cluster
- The node type
- Types of jobs that will run
- How busy the cluster will be
- Refer to maprdocs.mapr.com for details
Basic Requirements for All Nodes
- 64-bit processor(s)
- Supported OS
- RHEL or CentOS 6.1 or later
- SUSE 11 SP2 or later
- Ubuntu 12.04 or later
- Oracle Enterprise Linux 6.4 or later
- Java installed (requires JDK, not just JRE)
- Sun Java JDK 1.7 or 1.8
- OpenJDK 1.7 or 1.8
- Sync to an internal NTP server
- Unique hostname for each node
hostname –freturns appropriate values
- Resolvable with all other nodes with both forward and reverse DNS lookup
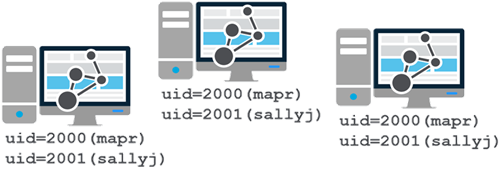
- Identical credentials and UID/GID on each node, for any cluster user
- MapR administrative user (
maprby default) is created during install if it does not exist
- MapR administrative user (
- Common unified authentication on all nodes
Memory Requirements
- Other recommendations:
- Do not use numad (Non-Uniform Memory Access Daemon)
- Set
vm.overcommit_memory=0 in /etc/sysctl.conf
Cluster Storage
- Raw, unformatted disks
- Best: three or more disks per data node
- Same size and speed
- Recommendations( due to unnecessary overhead on cluster performance):
- Do not use RAID
- Do not use LVM (Logical Volume Manager)
Cluster Storage Requirements
- Determine size of data
- Multiply by replication factor
- Default is
3
- Default is
25%overhead- Log data, MapReduce data, temp files

Local File System Requirements
Local Storage
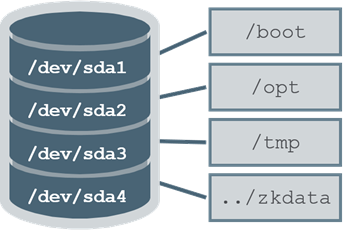
- Put some directories on their own partition
/opt(at least128GB)/tmp(at least10GB)/opt/mapr/zkdata(about500MB)
- Swap space:
24to128GB~110%of physical memory
Boot Drive
- Use LVM; its a good idea to use LVM on boot drive, but it should not be used on cluster storage
- Easily grow file systems later
- Mirror the boot disk
- Facilitate recovery in case of failure
Network Ports Used by MapR
- Port
9443: UI installer - Port
8443: MapR Control System - Full list in online documentation
Pre- and Post-Install Tools
MapR tools used for pre-install and post-install tests available here
Audit the Cluster
- Ensure prerequisites are met
- Identify component disparities:
- Disk size, cache, rpm
- Disk controller issues/bottlenecks
- Number of drives per controller
Test Nodes
Pre-Installation Testing
- Start with subsystem components in good order
- One slow node can drag down performance
- Establish performance reference values
- Identify component disparities
- End goal: get as much work through cluster as you can with minimal downtime
Pre-Install Tests
stream
- Tests memory and gives clues to CPU performance
- Measures sustainable bandwidth, not peak performance
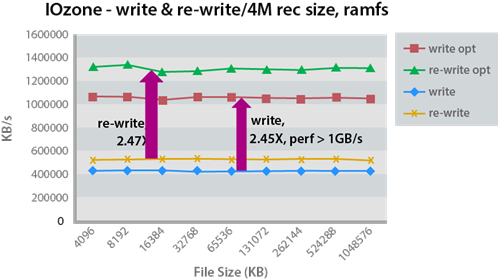
IOzone
- Destructive read/write test
- Run multiple times to verify repeatability
- Look for bottlenecks
rpctest
- MB/sec network can handle
- Upper bound for the link
- Test between pairs of nodes
- Point-to-point connections
- Test multiple node pairs concurrently
- Look for same results as sequential test
- Indicates how well switches are working
Plan the Service Layout
Service Layout Considerations
- MapR runs on clusters of one-two nodes
- High Availability (HA) requires three or more, since ZooKeeper must be installed on an odd number of nodes
- Rough size range:
- Small (
< 10nodes) - Medium (
10-25nodes) - Large cluster (
25up to1000s of nodes)
- Small (
- Not all services required
- Layout will evolve over time
- Add/remove services
- Plan initially, then monitor to see if service changes are needed
- The role of each service
- How many of each are essential
- How many needed for High Availability (HA)
- Resource requirements for services
- The size of your cluster
Overview of Services
 To see the services configured for a node, view
To see the services configured for a node, view /opt/mapr/roles
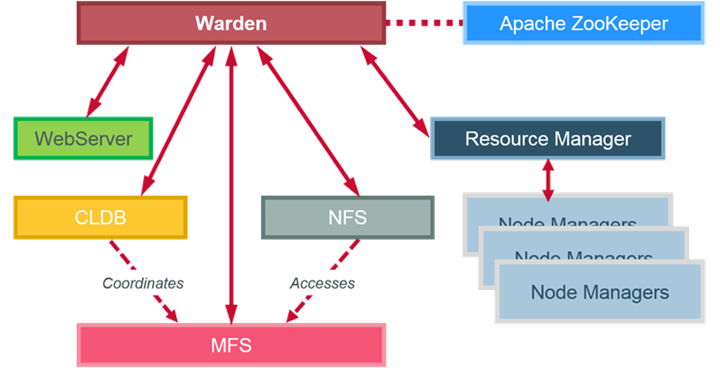
Services: ZooKeeper
- Coordinates other services
- Provides:
- Distributed and synchronised configuration
- Storage and mediation of configuration information
- Resolution of race conditions
- Runs on an odd number of nodes
- One, three, or five on separate nodes
- A quorum (majority) must be up
- Start before other services
- Run on control nodes, or control-as-data nodes
Services: Warden
- Coordinates cluster services
- Light Java application
- Runs on all nodes
- A MapR-specific service
- Job on each node is to:
- Start, stop, restart services (except ZooKeeper)
- Allocate memory to services
Services: CLDB
- Tracks and dispenses container information
- Replaces NameNode
- Can be one to three
- Two required for HA
- Master CLDB accessed for writes
- Other CLDBs on standby and accessed for reads
- Automatically restarted on failure
- No data or job loss
- CLDB failover is automatic with Converged Enterprise Edition
- Different procedure for Converged Community edition
- Run on control nodes, or control-as-data nodes
Services: ResourceManager and NodeManager
ResourceManager
- Manages cluster resources
- Schedules applications for YARN
- Two required for HA
- Prefer three on large clusters
- One active, others standby
- Run on control nodes, or control-as-data nodes
NodeManager
- Works with ResourceManager to manage YARN resource containers
- One per data node and control-as-data node
Services: MapR File Server
- MapR FileServer (MFS) manages disk storage
- Run on all nodes that store data
- Must run on any CLDB nodes
- Even control nodes
More Services
- NFS provides read/write Direct Access NFS™
- Recommended for all nodes
- HistoryServer archives MapReduce job metrics and metadata
- One per cluster; typically on a control node
- Webserver provides access to the MCS (MapR Control System)
Running Services on the Same Node
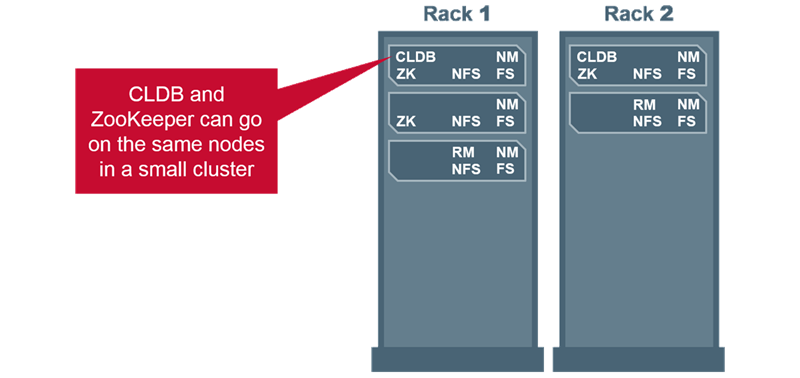
CLDB and ZooKeeper
- On small clusters, may need to run CLDB and ZooKeeper on the same node.
- On medium clusters, assign to separate nodes.
- On large clusters, put on separate, dedicated control nodes.
ResourceManager and ZooKeeper
- Avoid running ResourceManager and ZooKeeper together
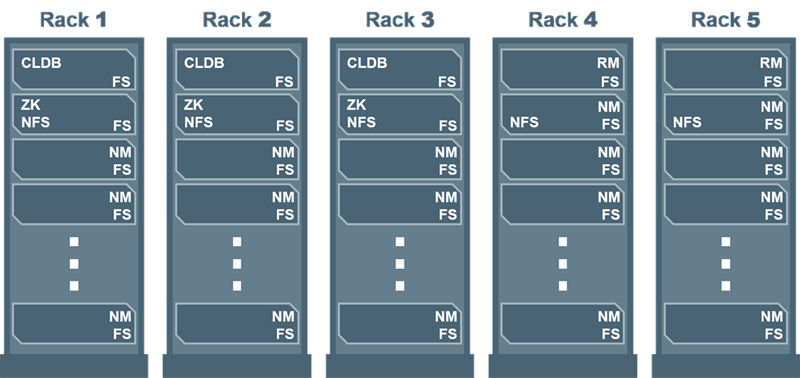
- With more than 250 nodes, run ResourceManager on dedicated nodes
Service Guidelines for Large Clusters
- Avoid running MySQL Server or webserver on a CLDB node
Sample Service Layouts
Small HA Cluster
Large HA Cluster
Leave a Comment